Zero Downtime SaaS Provider — How to Easily Deploy MySQL Clusters in AWS and Recover from Multi-Zone AWS Outages
This is the second post in a series of blogs in which we cover a number of different Continuent Tungsten customer use cases that center around achieving continuous MySQL operations with commercial-grade high availability (HA), geographically redundant disaster recovery (DR) and global scaling – and how we help our customers achieve this.
This use case looks at a multi-year (since 2012) Continent customer who is a large Florida-based SaaS provider dealing with sensitive (HIPAA Compliant) medical data, which offers electronic health records, practice management, revenue cycle management and data analytics for thousands of doctors.
What is the Challenge?
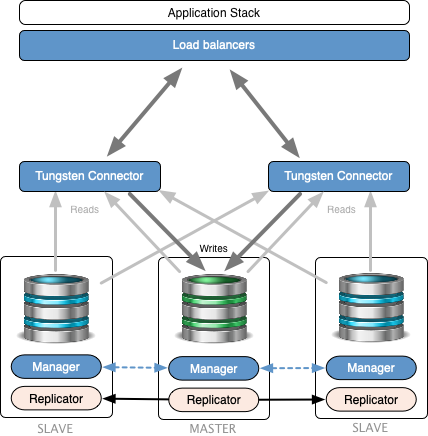
Lack of high availability in AWS. The challenge they were facing came from using AWS, which allowed them to rapidly provision database and …
[Read more]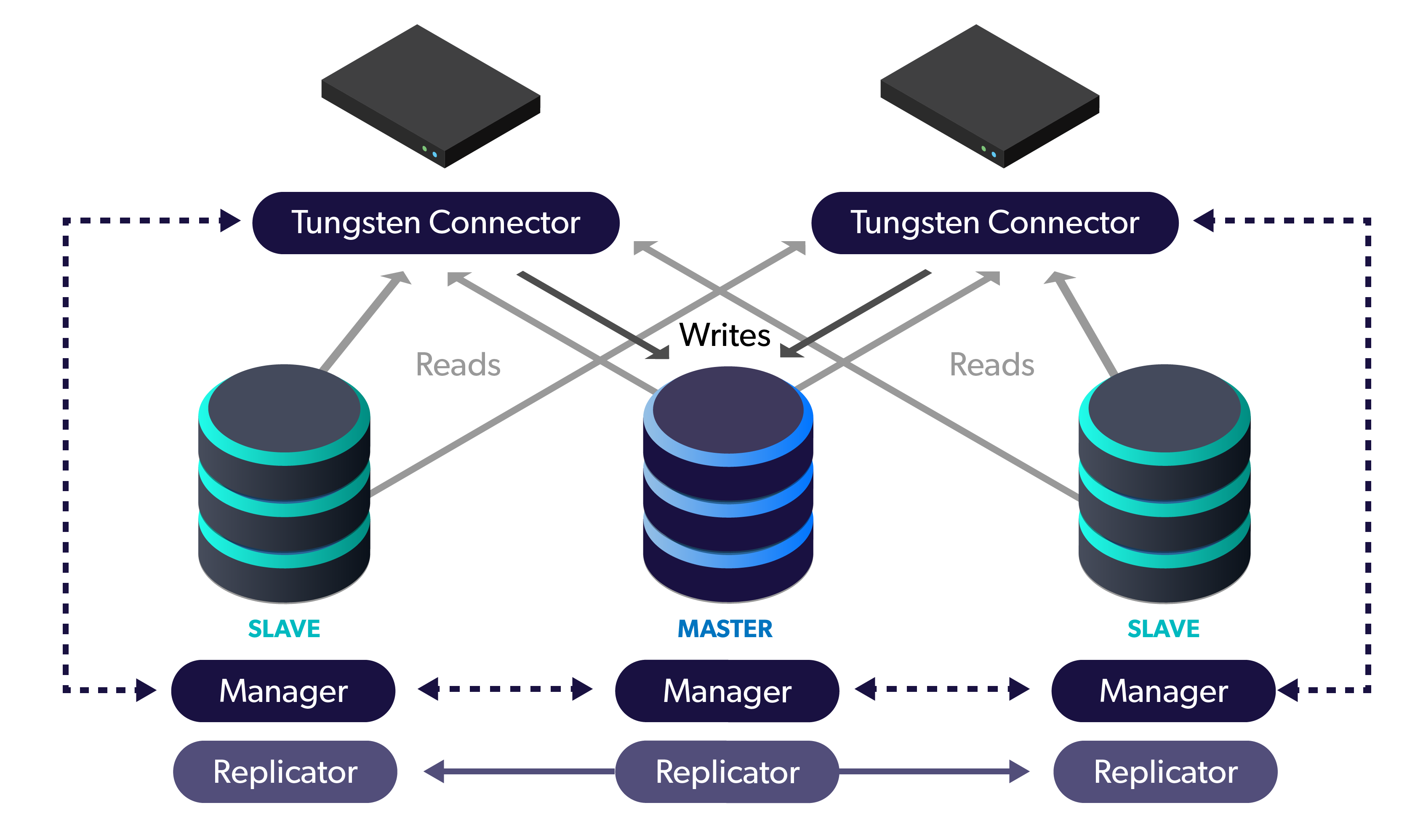{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}