Last week Solutions Linux / Open Source event was held in
Paris.
Kuassi MENSAH (Head of Product Management Database Technologies,
Oracle Corporation) presented the open source Oracle strategy.
Linux, MySQL, virtualization, GlassFish, Eclipse, dynamic
scripting languages ,... etc . It was well received by the
audience. Knowing that MySQL organization will be kept safe in
Oracle is perceived as a nice move.
Florian Haas(LINBIT) gave a tutorial on DRBD and did some demos
with NFS and video streaming. And of course he reminded people
that now since Linux 2.6.33, DRBD is officially integrated into
the Linux kernel source. DRBD making the push for mainline Linux kernel
is going to make HA easier.
...
[...]
I have been talking about this for a while, now at last I have
found the time to get started! Below is a picture from my 2008
MySQL User Conference presentation. It illustrates how engine
level replication works, and also shows how this can be ramped up
to provide a multi-master HA setup.
What I now have running is the first phase: asynchronous
replication, in a master/slave configuration. The way it works is
simple. For every slave in the configuration the master PBXT
engine starts a thread which reads the transaction log, and
transfers modifications to a thread which applies the changes to
PBXT tables on the slave.
Where to get it
I have pushed the changes that do this trick to PBXT 2.0 on
Launchpad. The branch to try out is …
{kind=link}
by @botchagalupe
on Virtualization, Open Source tools and DNS Problems
Technorati Tags: dnsproblem drupal ha heartbeat linux-ha mysql pacemaker puppet virtualization xen …
[Read more]I will be presenting a free Webinar on Geographic Replication for MySQL Cluster at 9:00 am (UK time) on Tuesday 24 November.
{kind=link}
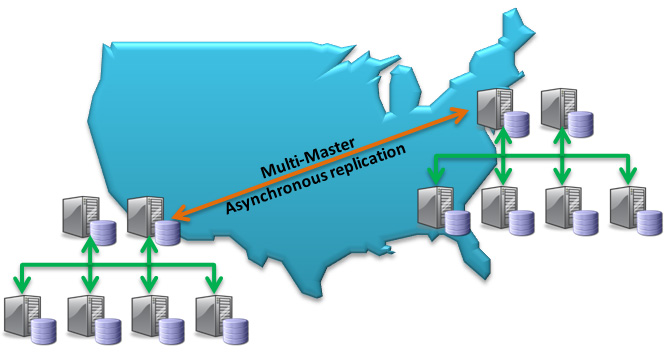
Multi-Master Replication for HA with MySQL Cluster
MySQL Cluster has been deployed into some of the most demanding
web, telecoms and enterprise /
government workloads, supporting 99.999% availability with real
time performance and linear write scalability.
You can register on-line here.
Tune into this webinar where you can hear from the MySQL Cluster product management team provide a detailed “deep dive” into one of MySQL Cluster’s key capabilities – Geographic Replication.
In this session, you will learn how using Geographic Replication enables your …
[Read more]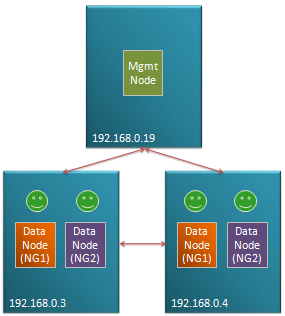{kind=link}
Fig 1. Typical management configuration
MySQL Cluster is designed to be a High Availability, Fault Tolerant database where no single failure results in any loss of service.
This is however dependent on how the user chooses to architect the configuration – in terms of which nodes are placed on which physical hosts, and which physical resources each physical host is dependent on (for example if the two blades containing the data nodes making up a particular node group are cooled by the same fan then the failure of that fan could result in the loss of the whole database).
Of course, there’s always the possibility of an entire data center being lost due to earthquake, sabotage etc. and so for a fully available system, you should consider using asynchronous replication to a geographically remote Cluster.
Fig 1. …
[Read more]
MySQL Enterprise Monitor is a tool to watch and analyze multiple
MySQL environments from a single web based dashboard. More
information is available on the MySQL homepage. Each MySQL instance is monitored
by a small agent that connects to the MySQL instance and reads
statistics that is sent to the MySQL Enterprise Monitor (MEM)
Server.That setup is very easy. But if the MySQL server is in a
cluster failover configuration, there are some things to consider
when installing the MEM agent:
What do you want?
Do you want to have two entries in the MEM dashboard for both
physical servers?This is good because: …
The goal is to have only one entry in the Enterprise Monitor Dashboard that shows the status of the MySQL instance, no matter on which physical server in runs. There are two ways to achieve this:
- You can install the agent on both physical nodes
- You can install the agent on a shared storage.
In either case you have to make sure, that only one agent runs at
a time. You have to integrate the agent into your cluster
framework. I will not describe how this works, as it is highly
dependant on your cluster framework.
The following description assumes, that you will install the
agent on both physical nodes.
- Install the agent but DO NOT START the agent yet.
- Edit the
[agent-installdir]/etc/mysql-monitor-agent.ini
In the [mysql-proxy] section add the following line:
agent-host-id=[logical hostname] - …
To install the MEM agent in a way that both physical servers are listed in the MEM dashboard, you have to install the agent on both physical nodes. But: Do not start the agent after the installation!There are three different IDs in MEM: agent-uuid, mysql-uuid and host-id. Usually they are generated automatically and you will never notice these IDs. For more information about the meaning of the different IDs look at this very good explanation from Jonathon Coombes.The agent stores the uuid and the hostid in a MySQL table called mysql.inventory. After a failover the other agent on the new node will notice "wrong" hostid and uuid entries in the inventory table. The agent will stop and ask you to TRUNCATE mysql.inventory. But with this procedure MEM creates a new instance, so all old data is lost. Not good for a failover environment.So in case of a …
[Read more]Funny how different experiences lead to different evaluations of tools. The MySQL HA solutions the MySQL Performanceblog list, are almost listed in the complete opposited order of what my impressions are.
Ok agreed, I should probably not put my MySQL NDB experiences
from 2-3 years ago with multiple Query of deaths and more
problems than you into account anymore , but back then went in
the list Less stable than a single node. I've had NDB POC setups
going down for much more than 05:16 minutes
Ndb comes with a lot of restrictions, there are
As for MySQL on DRBD, I've said this before , I love DRBD, but
having to wait for a long InnoDB recovery after a failover just
kills your uptime ,
…
|
|
The Spider storage engine should be already known to the community. Its version 2.5 has recently been released, with new features, the most important of which is that you can execute remote SQL statements in the backend servers. The method is quite simple. Together with Spider, you also get an UDF that executes SQL code in a remote server. You send a query with parameters saying how to connect to the server, and check the result (1 for success, 0 for failure). If the SQL involves a SELECT, the result can be sent to a temporary table. Simple and effective. |
In addition to the Spider engine, Kentoku SHIBA has also created
the …