In life there are really two major types of data analytics. Firstly, we don’t know what we want to know – so we need analytics to tell us what is interesting. This is broadly called discovery. Secondly, we already know what we want to know – we just need analytics to tell us this information, often repeatedly and as quickly as possible. This is called anything from reporting or dashboarding through more general data transformation and so on.
Typically we are using the same techniques to achieve this. We shove lots of data into a repository of some from (SQL, MPP SQL, NoSQL, HDFS etc) then run queries/ jobs/ processes across that data to retrieve the information we care about.
Now this makes sense for data discovery. If we don’t know what we want to know, having lots of data in a big pile that we can slice and dice in interesting ways is good. But when we already know what …
[Read more]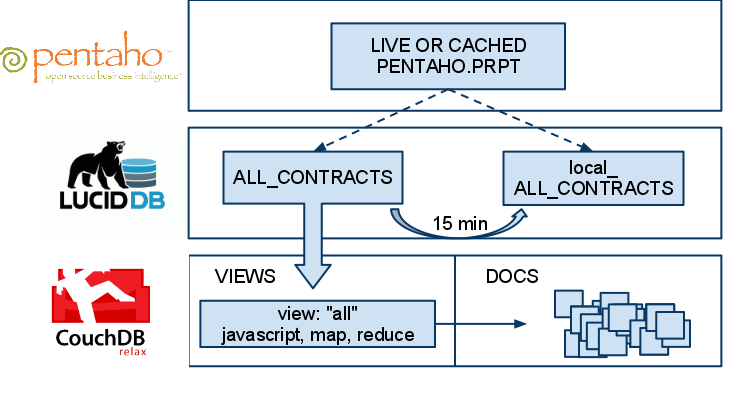{kind=link}