|
The Open Database Camp 2011 is shaping up nicely. The logistics is being defined and local and international volunteers are showing up for help. (Thanks, folks!) If you want to start booking, there is a list of hotels in the Accommodation page. And don't forget to sign up in the Attendees list. Local travel information will be released as soon as we finish cranking up the plan. Open Database camp is free, but we still have expenses to get the job done. We need both official sponsors and … |
Feb
03
2011
Jan
31
2011
Virtual IP addresses or VIPs are commonly used to enable
database high availability. A standard failover
design uses an active/passive DBMS server pair connected by
replication and watched by a cluster manager. The active
database listens on a virtual IP address; applications use it for
database connections instead of the normal host IP address.
Should the active database fail, the cluster manager promotes the
passive database server and shifts the floating IP address to the
newly promoted host. Application connections break and then
reconnect to the VIP again, which points them to the new
database.
| VIP-Based Database Availability Design |
{kind=link}
Virtual IP addresses are enticing …
[Read more]
Jan
29
2011
InnoDB’s checkpoint algorithm is not well documented. It is too complex to explain in even a long blog post, because to understand checkpoints, you need to understand a lot of other things that InnoDB does. I hope that explaining how InnoDB does checkpoints in high-level terms, with simplifications, will be helpful. A lot of the simplifications are because I do not want to explain the complexities of how the simple rules can be tweaked for optimization purposes, while not violating the ACID guarantees they enforce.
A bit of background: Gray and Reuter’s classic text on transaction processing introduced two types of checkpoints beginning on page 605. There is a sharp checkpoint, and there is a fuzzy checkpoint.
A sharp checkpoint is accomplished by flushing all modified pages for committed transactions to disk, and …
[Read more]
Jan
13
2011
{kind=link}
Jan
11
2011
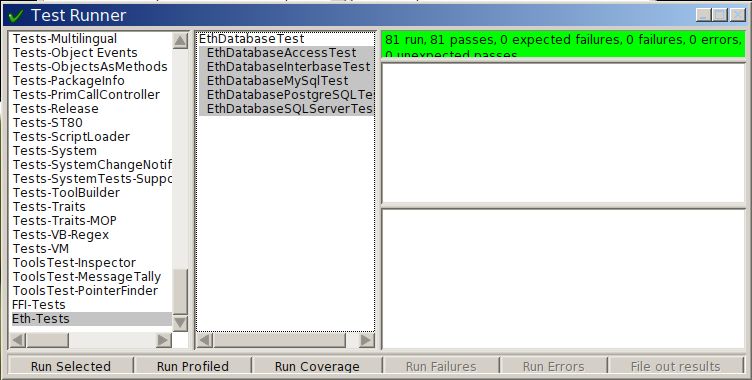
Brief pause of that Sudoku series : I’m working on my object-relational mapping framework code-named Eth.
It’s vaguely similar to Glorp but much simpler and not as intelligent as Glorp. This time, the resurrection of my framework is more like… a rewrite from scratch. It all started on VAST, then I ported it to Dolphin then Squeak and now Pharo. Hopefully, now I will spend more time writing it than porting it! Also, it will exclusively support Pharo. I also decided to write some SUnit tests to make sure I can properly handle PostgreSQL, MySQL and Interbase for the first version. But I am also planning on supporting SQL Server, Oracle, DB2, Access and Firebird. Eventually!
Besides, I’m also …
[Read more]
Jan
05
2011
|
I have been traveling to many conferences in the last 10
years, and many times I have been asked to organize an event
in my native land, Sardinia. After delaying the inevitable for
long time, here I can announce it. The Open Database Camp
2011 will take place in Sardinia, hosted by the Sardinia Technology Park, a local scientific
and business institution with international links. Mark your calendars: the Open Database Camp will be held in Sardinia on May 6-7-8, 2011. I have already confirmed the venue, and I will have full cooperation from Sardegna Ricerche about the conference logistics. I will meet the organizers on … |
Jan
02
2011
One of the query optimization scenarios I’ve seen a lot over the years is finding something within some distance from a point. For example, finding people within some distance of yourself, apartments in a radius from a postal code, and so on.
These queries usually use the great-circle formula. That might be because Google finds lots of pages claiming that this is the right way to do a radius search. “The earth is not flat!”, they all say. That’s true, but it doesn’t mean that the great-circle formula is a good approach. It’s usually a really bad approach, in fact. It’s needlessly precise for most things, not precise enough for others, and it’s an expensive query to execute; all the trig functions tend to eat a bunch of CPU, and make it impossible to use ordinary indexes. This is true for all of the databases I’ve used — MySQL, Postgres, and SQL Server.
The great-circle formula is needlessly precise for a few …
[Read more]
Dec
19
2010
O’Reilly’s 2011 edition of the MySQL conference has an expanded agenda, with good representation from Postgres, CouchDB, MongoDB, and others. Take a look at the full schedule listing, which is being filled out as talks are approved and the speakers verify that they’ll give the session.
I am certainly looking forward to this year’s event. A tremendous amount of progress has landed in GA versions of open-source databases this year. To name just a couple, there’s a new version of Postgres (9.0) with built-in replication and many more improvements; there’s MySQL 5.5 GA; there’s the HandlerSocket NoSQL interface to MySQL; Drizzle has a beta release; and the list goes on. I believe that this conference will have balanced and representative coverage of what’s really important to users. …
[Read more]
Dec
18
2010
My recent account of The State of MySQL forks seems to have gotten quite a lot of attention. I promised to follow up with a separate piece about Drizzle and also PostgreSQL, as the other major open source database, so I'd better keep that promise now.
Dec
13
2010
Over the last few months I have been pleasantly surprised by the
number of people using open source builds of Tungsten. My
company, Continuent, has therefore started to offer support for
open source users and will likely expand these services to meet
demand.
There have also been a number of requests to add specific
features to open source builds, especially for replication. We
have added a few already but are now considering pushing even
more features into open source if we can find sponsors.
These add to a number of great features already in open source
like global transaction IDs, MySQL 5.0/5.1, basic drizzle
replication, transaction filtering, and many others.
Do you have special replication or clustering features you would
like to see added to Tungsten? Specialized MySQL to PostgreSQL
replication? Management and monitoring commands? Cool
parallel replication problems? …