On the new milestone release MySQL 5.7.2, we did some
optimizations on binlog lock and dump thread. Major
dump thread code was re-written: Some code never reached was
removed; Complex
logic was simplified; Code became more readable. But I don't want
to introduce the refactoring here. Today, I would like to
introduce you the optimization on binlog lock which improved
master throughput.
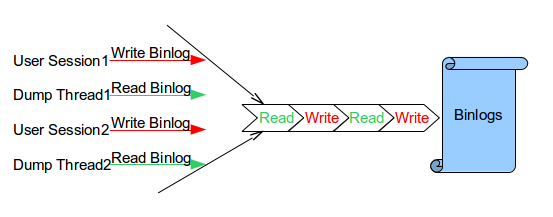
Background binlog lock(LOCK_log) is a mutex which is used to
protect binlog read and write operations. With this mutex, binlog
read and write operations are safe. But it has limited
concurrency. Not only can dump threads and user sessions not read
and write binlog simultaneously but even the dump threads
themselves cannot read the binlog simultaneously. All other sessions have to wait whenever one
session …
{kind=link}
Semi-synchronous replication is used by many users who want
improved data integrity. Today I would like to introduce a
semi-synchronous new feature on MySQL 5.7.2 milestone
release which enhances the data integrity between master and
slave.
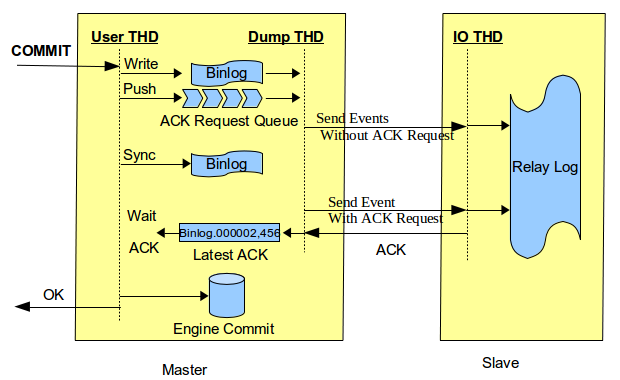
Wait Slave Acknowledgement before Engine Commit As you know, with
semi-synchronous replication enabled, user sessions will wait for
acknowledgement from a slave before committing the transaction.
To enhance data integrity, this feature makes transaction
sessions wait a little bit earlier than MySQL 5.5 and MySQL 5.6.
The wait happens just before the server commits to storage
engine.
With this feature, semi-synchronous replication is able to
guarantee:
{kind=link}
- All committed transaction are already replicated to at least …
Applications should be written taking into account that errors
will eventually happen and, in particular, database application
developers usually consider this while writing their
applications.
Although the concepts required to write such applications are
commonly taught in database courses and to some extent are widely
spread, building a reliable and fault-tolerant database
application is still not an easy task and hides some pitfalls
that we intend to highlight in this post with a set of
suggestions or tips.
In what follows, we consider that the execution flow in a
database application is characterized by two distinct phases:
connection and business logic. In the connection phase, the
application connects to a database, sets up the environment and
passes the control to the business logic phases. In this phase,
it gets inputs from a source, which may be an operator, another
application or a component within the same …
In this post, we are going to show how to develop fault-tolerant
applications using MySQL Fabric, or simply Fabric, which
is an approach to building high availability sharding
solutions for MySQL and that has recently become available
for download as a labs release (http://labs.mysql.com/). We are going to focus
on Fabric's high availability aspects but to find out more on
sharding readers may check out the following blog post:
Servers managed by Fabric are registered in a MySQL Server instance, called backing store, and are …
[Read more]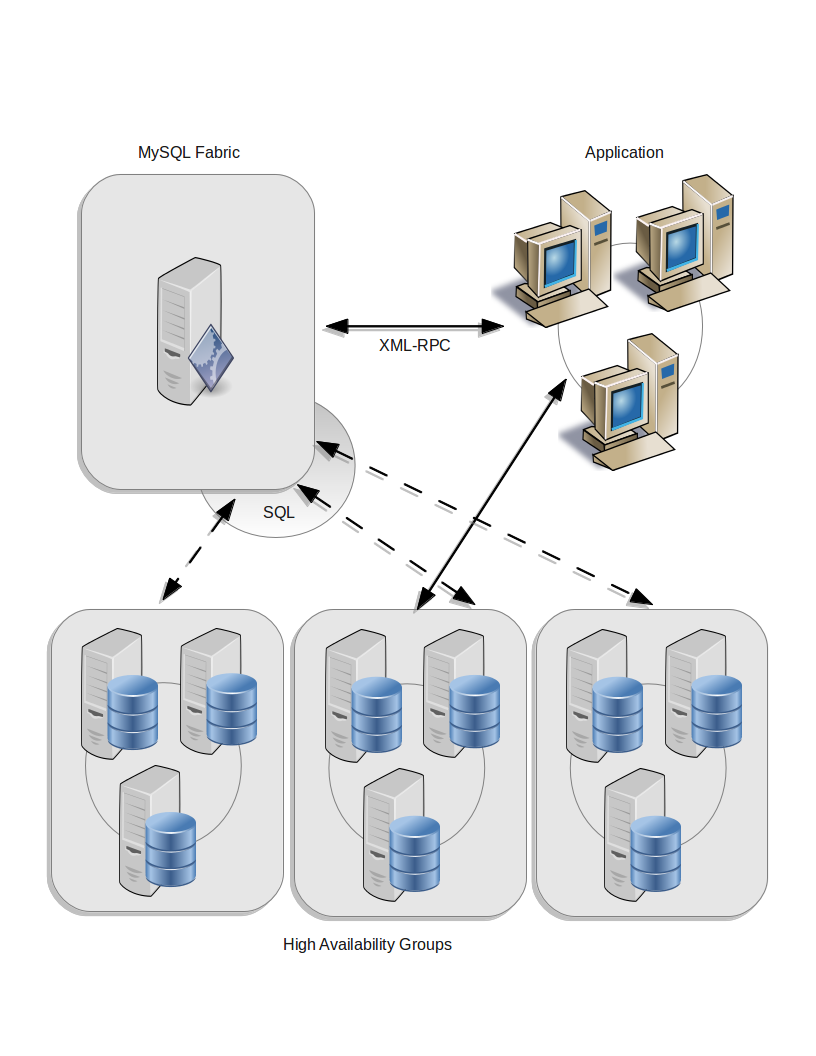{kind=link}
The occurrence of failures and crashes can compromise the high
availability of your database system affecting your revenue and
reputation. Therefore, it is fundamental to minimize downtime and
have an efficient strategy for crash recovery.
Replication and failover are commonly applied to deal with those
situations. However, other types of failures can also affect the
recovery process. In fact, the occurrence of unanticipated faults
can really be an headache! Thus, it is better to be prepared and
implement a good fault-tolerant failover strategy.
Performing failover is not trivial. It requires the execution of
several steps in order to ensure data consistency (i.e., no data
loss) -- especially if the "best" candidate to become the new
master is not the most up-to-date.
Note that, one might desire that the slave with the best hardware
should become the new master. In this case, the candidate must be …
Working day to day with Percona Remote DBA customers, we have been facing an issue from time to time when MySQL replication lag is flapping between 0 and XXXXX constantly – i.e. Seconds_Behind_Master is 0 for a few secs, then it’s like 6287 or 25341, again 0 and so on. I would like to note the 5 different scenarios and symptoms of this – some are obvious and some are not really.
1. Duplicate server-ids on two or more slaves.
Symptoms: MySQL error log on a slave shows the
slave thread is connecting/disconnecting from a master
constantly.
Solution: check whether all nodes in the
replication have unique server-ids.
2. Dual-master setup, “log_slave_updates” enabled, server-ids changed.
Scenario: you stop MySQL on the first master, then you stop the second one. …
[Read more]I was rooting through past blog entries and I stumbled accross a draft post on setting up multi-master (update anywhere) asynchronous replication for MySQL Cluster. The post never quite got finished and published and while the material is now 4 years old it may still be helpfull to some and so I’m posting it now. Note that a lot has happened with MySQL Cluster in the last 4 years and in this area, the most notable change has been the Enhanced conflict resolution with MySQL Cluster active-active replication feature introduced in MySQL Cluster 7.2 and if you’re only dealing with a pair of Clusters, that’s your best option as it removed the need for you to maintain the timestamp columns and backs out entire transactions rather than just the conflicting rows. So when would you use this “legacy” method? The main use case is when you want conflict detection/resolution among a ring of more than …
[Read more]It was just a few days ago that we announced, with celebratory enthusiasm, Tungsten Replicator 2.1.1, and today we are at it again, with Tungsten Replicator 2.1.2.
What happened? In a surfeit of overconfidence, we released Tungsten 2.1.1, with faith on the test suite and its result. The faith was justified, as the test suite was able to catch any known problem and regression. The overconfidence was unjustified, because, due to a series of unfortunate events, some sections of the test suite were accidentally disabled, and the regression that was lurking in the dark was not caught.
Therefore, instead of having a quiet post-release week-end, the whole team has worked round the clock to plug the holes. There …
[Read more]
MySQL Connect 2013 is coming up with several interesting new
sessions. Some sessions that I am participating in got accepted
for the conference, so if you are going there, you might find the
following sessions interesting. For your convenience, the
sessions have hCalendar markup, so it should be easier to
add them to your calendar.
- MySQL Sharding, Replication, and HA (September 21, 5:30-6:30pm in Imperial Ballroom B)
-
This session is an opportunity for you to meet the MySQL engineering team and discuss the latest tools and best practices for sharding MySQL across distributed server farms while maintaining high availability.
Come …
A tip for all those cloud users that like cloning database servers (as reported in my book Effective MySQL – Replication Techniques in Depth).
Starting with MySQL 5.6, MySQL instances have a UUID. Cloning servers to quickly create slaves will result in the following error message.
mysql> SHOW SLAVE STATUSG ... Last_IO_Error: Fatal error: The slave I/O thread stops because master and slave have equal MySQL server UUIDs; these UUIDs must be different for replication to work. ...
The solution is simple. Clear our the file based configuration file (located in the MySQL datadir) and restart the MySQL instance.
$ rm -f /mysql/data/auto.cnf $ service mysql restart