Following requests received during earlier MySQL Cluster webinars, a new (and as always, free) webinar has been scheduled which focuses on MySQL Cluster Replication. The webinar is scheduled for Thursday 10 September and you can register at http://www.mysql.com/news-and-events/web-seminars/display-415.html
I’ll be on-line during the webinar, answering questions.
Details….
MySQL Cluster: Geographic Replication Deep-Dive
Thursday, September 10, 2009
MySQL Cluster has been deployed into some of the most demanding web, telecoms and enterprise / government workloads, supporting 99.999% availability with real time performance and linear write scalability.
Tune into this webinar where you can hear from the Director of MySQL Server Engineering provide a detailed “deep dive” …
[Read more]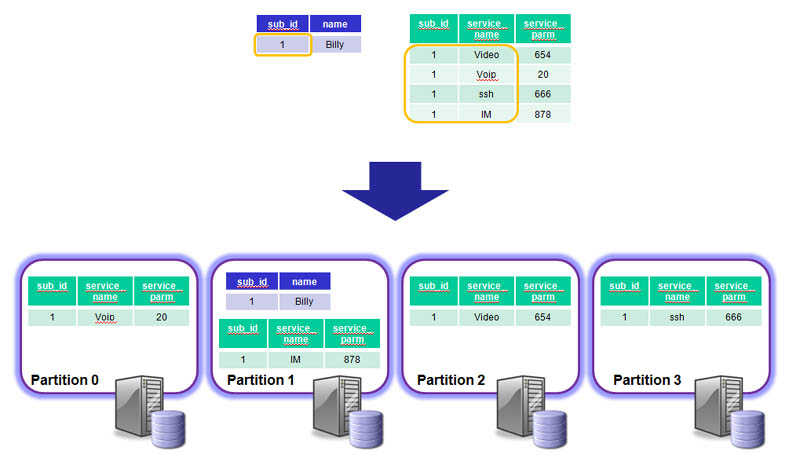{kind=link}
{kind=link}
{kind=link}