Tungsten Clustering is an extraordinarily flexible tool, with options at every layer of operation.
In this blog post, we will describe and discuss the two different methods for installing, updating and upgrading Tungsten Clustering software.
When first designing a deployment, the question of installation methodology is answered by inspecting the environment and reviewing the customer’s specific needs.
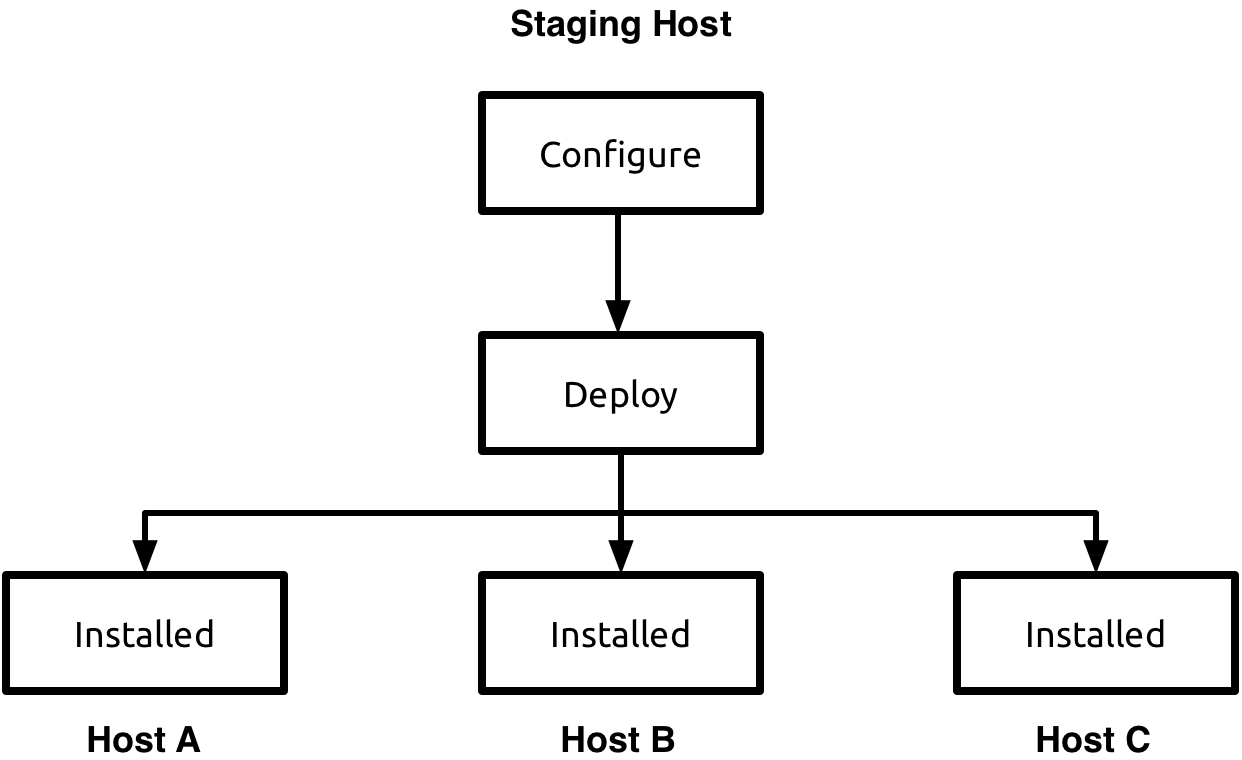
Staging Deployment Methodology
{kind=link}
All for One and One for All
Staging deployments were the original method of installing
Tungsten Clustering, and relied upon command-line tools to
configure and install all cluster nodes at once from a central
location called the staging server.
This staging server (which could be one of the cluster nodes) requires SSH access to all …
[Read more]{kind=link}