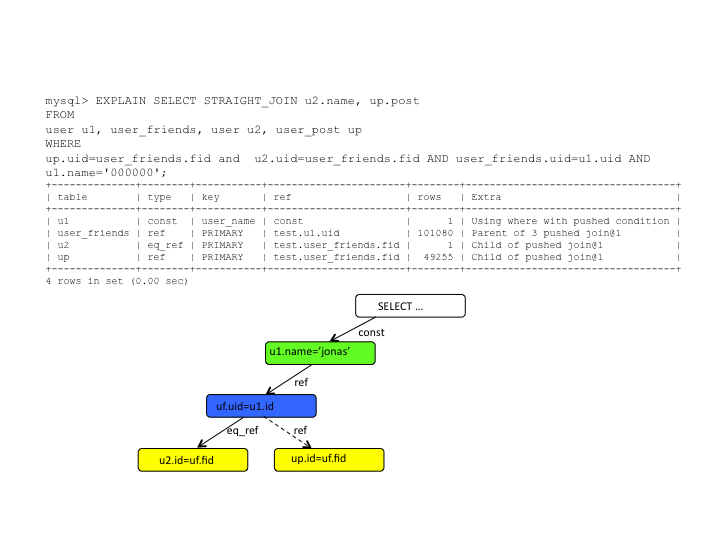
I worked on an issue last recently where a query was too slow when executed in MySQL Cluster. The issue was that Cluster has some restrictions when it comes to push down conditions.
As an example of this, consider the following query using the employees sample database. The query takes a look at the average salary based on how many years the employee has been with the company. As the latest hire date in the database is in January 2000, the query uses 1 February 2000 as the reference date.
Initially the query performs like (performance is with two data
nodes and all nodes in the same virtual machine on a laptop, so
the timings are not necessarily representative of a production
system, though the improvements should be repeatable):
mysql> SELECT FLOOR(DATEDIFF('2000-02-01', hire_date)/365) AS LengthOfService,
COUNT(DISTINCT employees.emp_no) AS NoEmployees, AVG(salary) AS AvgSalary
FROM salaries …[Read more]
{kind=link}
{kind=link}