This is a follow-up post in the MySQL Master Replication Crash Safety series. In the previous posts, we explored the consequences of reducing durability on masters (different data inconsistencies after an OS crash depending on replication type) and the performance boost associated with this configuration (benchmark results done on Google Cloud Platform / GCP). The consequences are summarised in
Jul
16
2019
Jul
09
2019
This is a follow-up post in the MySQL Master Replication Crash Safety series. In the three previous posts, we explored the consequence of reducing durability on masters (including setting sync_binlog to a value different from 1). But so far, I only quickly presented why a DBA would run MySQL with such configuration. In this post, I present actual benchmark results. I also present a
Jul
04
2019
The Question Recently, a customer asked us:
After importing a new section of user data into our Tungsten
cluster, we are seeing perpetually rising replication lag. We are
sitting at 8.5hrs estimated convergence time after importing
around 50 million rows and this lag is climbing continuously. We
are currently migrating some of our users from a NoSQL database
into our Tungsten cluster. We have a procedure to write out a
bunch of CSV files after translating our old data into columns
and then we recursively send them to the write master using the
mysql client. Specifically our import SQL is doing LOAD
DATA LOCAL INFILE and the reading in a large CSV file to
do the import. We have 20k records per CSV file and we have 12
workers which insert them in parallel.
Simple Overview The Skinny
In cases like this, the slaves are having trouble with the database unable to keep up with the apply stage …
[Read more]
Jun
29
2019
Quickly configure replication using DBdeployer [SandBox]
We might have different scenarios when we need a quick setup of
replication either between the same version of MySQL (Like 8.0
--> 8.0) or between the different version of MySQL (Like 5.7
--> 8.0) to perform some testings.
Here in this blog post, I will explain how we can create our
replication lab setup quickly using the virtual machine and
DBdeployer tool.
Let's see, how to create replication between the same version and
different version of MySQL using DBdeployer step by
step.
Create CentOS VM Please find my …
{kind=link}
Jun
17
2019
So MySQL's group replication came out with MySQL 5.7. Now that is
has been out a little while people are starting to ask more about
it.
- https://dev.mysql.com/doc/refman/8.0/en/group-replication.html
- https://dev.mysql.com/doc/refman/8.0/en/group-replication-deploying-in-single-primary-mode.html
Below is an example of how to set this up and a few pain point
examples as I poked around with it.
I am using three different servers,
Server CENTOSA
mysql> INSTALL PLUGIN group_replication SONAME
'group_replication.so';
Query OK, 0 rows affected (0.02 sec)
vi my.cnf
…
May
31
2019
Ok, so if you’re reading this, then I can guess you’ve got a MySQL InnoDB Cluster in an awkard shape, i.e. you need to restore a backup and add the instance back into the cluster, so we have all our instances again.
As it might be logical to think “ah, but I’ve only lost 1 instance, a read-only instance, so all I have to do is backup & restore the other read-only instance and I’m home free. Well I want to make it a little harder. So in this scenario, assume that we’ve lost both the READ-ONLY instances, so I need to backup my primary READ-WRITE instance.
I’ve got a 8.0.16 instance, on Oracle Linux 7.4. We’ll be looking at 2 hosts, ic1 & ic3.
We’ll be using the MySQL Enterprise Edition Server, that bundles MySQL Enterprise Backup with the rpm’s so we don’t need to install anything else.
I’ll assume you’ve got access to Oracle …
[Read more]
May
28
2019
(In the previous post, Part 5, we covered Data Reads.)
In this blog post, we continue our series of exploring MyRocks mechanics by looking at the configurable server variables and column family options. In our last post, I explained at a high level how reads occur in MyRocks, concluding the arc of covering how data moves into and out of MyRocks. In this post, we’re going to explore replication with MyRocks, more specifically read-free replication.
Some of you may already be familiar with the concepts of read-free replication as it was a key feature of the TokuDB engine, which leveraged fractal tree indexing. TokuDB was similar to MyRocks in the sense that it had a pseudo log-based storage …
[Read more]
May
22
2019
{kind=link}
Overview The Skinny
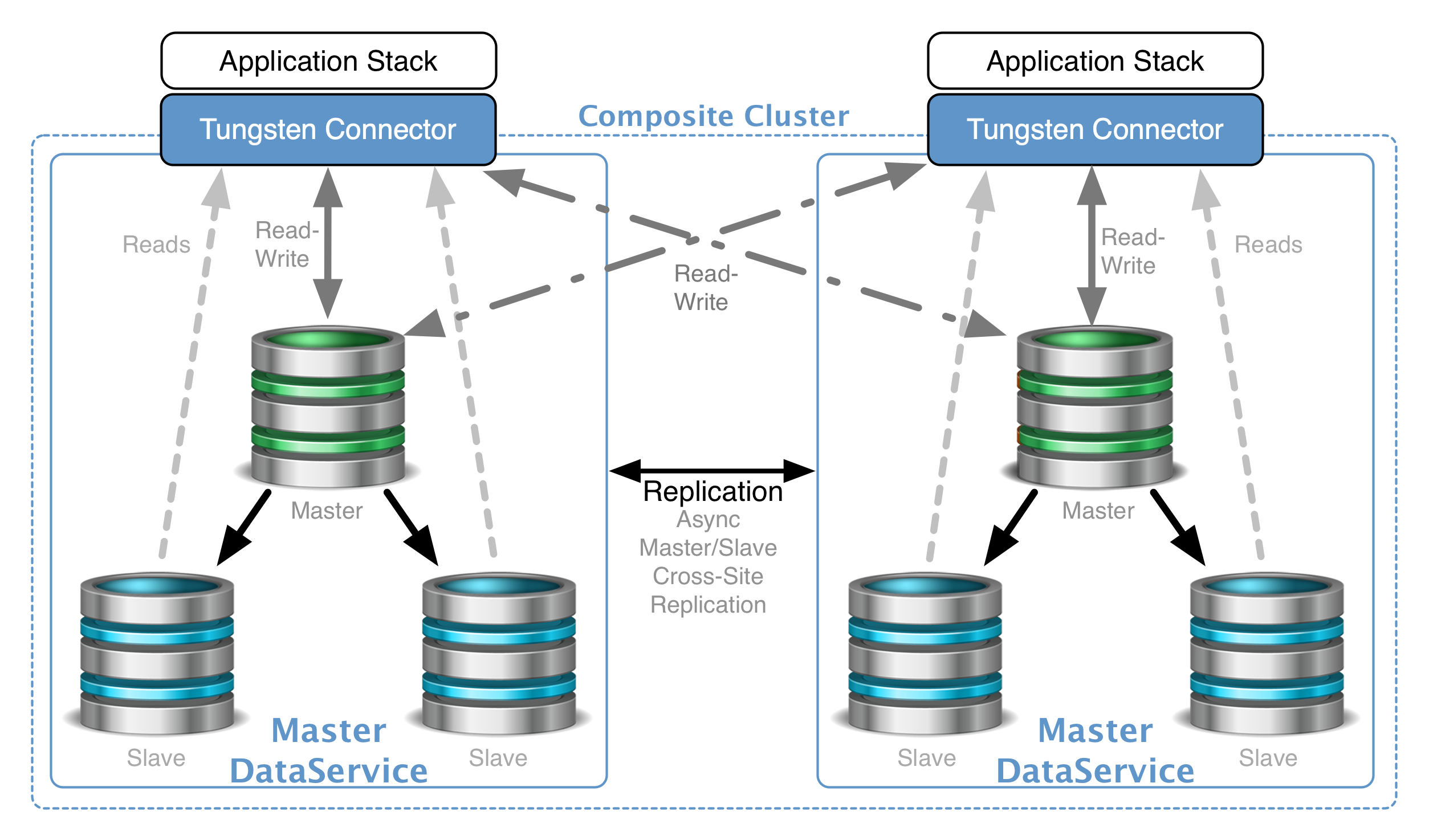
In this blog post we will discuss how the managed cross-site replication streams work in a Composite Multi-Master Tungsten Cluster for MySQL, MariaDB and Percona Server.
Agenda What’s Here?
- Briefly explore how managed cross-site replication works in a Tungsten Composite Multi-Master Cluster
- Describe the reasons why the default design was chosen
- Explain the pros and cons of changing the configuration
- Examine how to change the configuration of the managed cross-site replicators
Cross-Site Replication A Very Brief Summary
In a standard Composite Multi-Master (CMM) deployment, the managed cross-site replicators pull Transaction History Logs (THL) from every remote cluster’s current master node. …
[Read more]
May
22
2019
In this blog, we will see how to do a flashback recovery or rolling back the data in MariaDB, MySQL and Percona.
As we know the saying “All humans make mistakes”, following that in Database environment the data modified accidentally can bring havoc to any organisations.
Recover the lost data
- The data can be recovered from the latest full backup or incremental backup when data size is huge it could take hours to restore it.
- From backup of Binlogs.
- Data can also be recovered from delayed slaves, this case would be helpful when the mistake is found immediately, within the period of delay.
We can use anyone of the above ways or other that can help to recover the lost data, but what really matters is, What is the …
[Read more]
May
15
2019
File/Pos Replication : Skip Slave's sql_thread error
[COMMAND]
For binlog file & position based replication setup, To skip
the slave's sql_thread error, run below command.
stop slave; set global sql_slave_skip_counter=1; start
slave; select sleep(3); show slave status\G