Note: It was my first attempt using the MySQL UDF Api back then. The library is still maintained and got some new features. Check out the new MySQL Infusion UDF.
Nov
17
2010
Nov
16
2010
Although MyISAM has been the default storage engine for MySQL but its soon going to change with the release of MySQL server 5.5. Not only that, more and more people are shifting over to the Innodb storage engine and the reasons for that is the tremendous benefits, not only in terms of performance, concurrency, ACID-transactions, foreign key constraints, but also because of the way it helps out the DBA with hot-backups support, automatic crash recovery and avoiding data inconsistencies which can prove to be a pain with MyISAM. In this article I try to hammer out the reasons why you should move on to using Innodb instead of MyISAM.
Nov
08
2010
These are some of my notes from some sysbench in-memory r/o testing in past day or so:
- At ‘fetch data by primary key’ benchmark with separate read snapshots at each statement, MySQL shines until ~200 concurrent threads, then performance starts dropping slightly faster than one would want, I think mostly from table cache LOCK_open contention
- auto-commit cost (establishing read snapshot per statement) for SELECTs is ~10% for MySQL, but for PG it can be +50% in plain SQL mode and +130% (!!!!!!!) when using prepared statements (this can be seen in a graph – obviously the global …
Nov
05
2010
Starting with the great work of Yoshinori-san Using MySQL as a NoSQL – A story for exceeding 750,000 qps on a commodity server and Golan Zakai who posted Installing Dena’s HandlerSocket NoSQL plugin for MySQL on Centos I configured and tested HandlerSocket under Ubuntu 10.04 64bit.
NOTE: This machine already compiles MySQL and Drizzle. You should refer to appropriate source compile instructions for necessary dependencies.
# Get Software cd /some/path export DIR=`pwd` wget http://download.github.com/ahiguti-HandlerSocket-Plugin-for-MySQL-1.0.6-10-gd032ec0.tar.gz wget http://mysql.mirror.iweb.ca/Downloads/MySQL-5.1/mysql-5.1.52.tar.gz wget …[Read more]
Nov
05
2010
There are three simple practices that can improve general INSERT throughput. Each requires consideration on how the data is collected and what is acceptable data loss in a disaster.
General inserting of rows can be performed as single INSERT’s for example.
INSERT INTO table (col1, col2, col3) VALUES (?, ?, ?); INSERT INTO table (col1, col2, col3) VALUES (?, ?, ?); INSERT INTO table (col1, col2, col3) VALUES (?, ?, ?);
While this works, there are two scalability limitations. First is the network overhead of the back and forth of each SQL statement, the second is the synchronous nature, that is your code can not continue until your INSERT is successfully completed.
The first improvement is to use MySQL’s multi values capability with INSERT. That is you can insert multiple rows with a single INSERT statement. For example:
INSERT INTO table (col1, col2, col3) VALUES (?, ?, ?), (?, ?, ?), (?, ?, ?);…[Read more]
Nov
03
2010
From MySQL Cluster 7.1.9 (not yet released) it is possible to get
better stats on disk data tables. In fact, the statistics makes
it possible to tune the DiskPageBufferMemory
parameter (similar to innodb_bufferpool), in order to avoid disk
seeks. It is much (understatement) faster to fetch data from the
DiskPageBufferMemory than disk.
Here is an example/tutorial how to use this information and how
to check the hit ratio of the DiskPageBufferMemory.
Next time, I will explain about other counters you can get from
ndbinfo.diskpagebuffer.
Finally, no more educated guesswork is needed.
Let's take an example.
I have a table t1 with 650000 record
CREATE TABLE `t1` ([Read more]
`id` bigint(20) NOT NULL AUTO_INCREMENT,
`data1` varchar(512) DEFAULT NULL,
`data2` varchar(512) DEFAULT NULL,
PRIMARY KEY (`id`)
) …
Oct
30
2010
Pagination is used very frequently in many websites, be it search results or most popular posts they are seen everywhere. But the way how it is typically implemented is naive and prone to performance degradation. In this article I attempt on explaining the performance implications of poorly designed pagination implementation. I have also analyzed how Google, Yahoo and Facebook handle pagination implementation. Then finally i present my suggestion which will greatly improve the performance related to pagination.
Oct
29
2010
On Thursday, November 04, at
0900PST/1700CET/1600GMT there is a webinar about Pushed Down
Joins. This webinar will explain how Pushed Down Joins works, and
some performance numbers.
Register here: http://mysql.com/news-and-events/web-seminars/display-583.html.
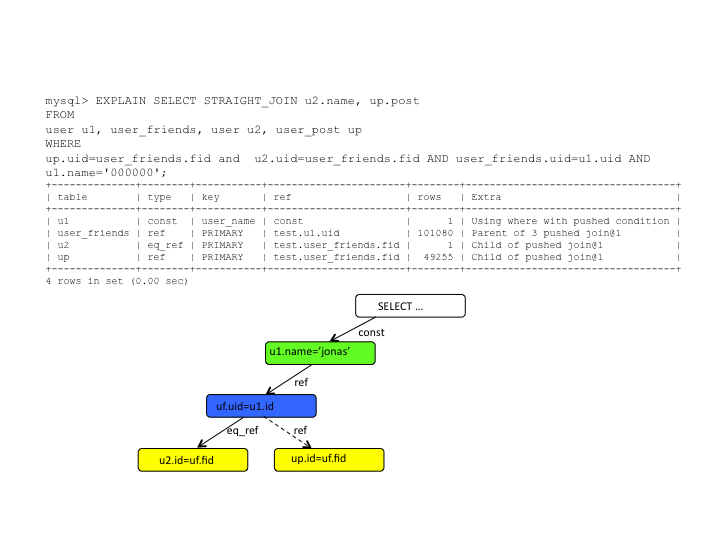
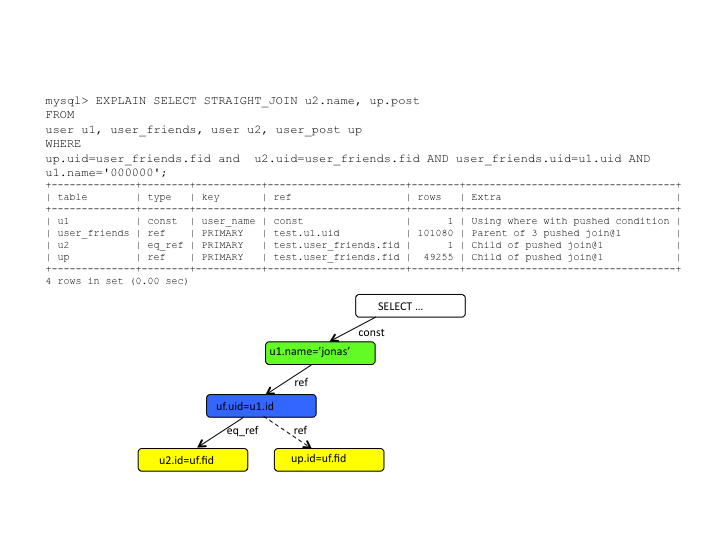
NDB Pushed JOINs means query shipping
instead of data shipping and it reduces drastically the network
hops between the MySQL Server and data nodes, which in turn gives
a tremendous performance improvement. For particular queries a
180x improvement has been measured.
{kind=link}
{kind=link}
Oct
25
2010
The parameter sort_buffer_size is one the MySQL parameters that is far from obvious to adjust. It is a per session buffer that is allocated every time it is needed. The problem with the sort buffer comes from the way Linux allocates memory. Monty Taylor (here) have described the underlying issue in detail, but basically above 256kB the behavior changes and becomes slower. After reading a post from Ronald Bradford (here), I decide to verify and benchmark performance while varying the size of the sort_buffer. It is my understanding that the sort_buffer is used when no index are available to help the sorting so I created a MyISAM table with one char column without an index:
PLAIN TEXT CODE:
- …
Oct
22
2010
{kind=link}
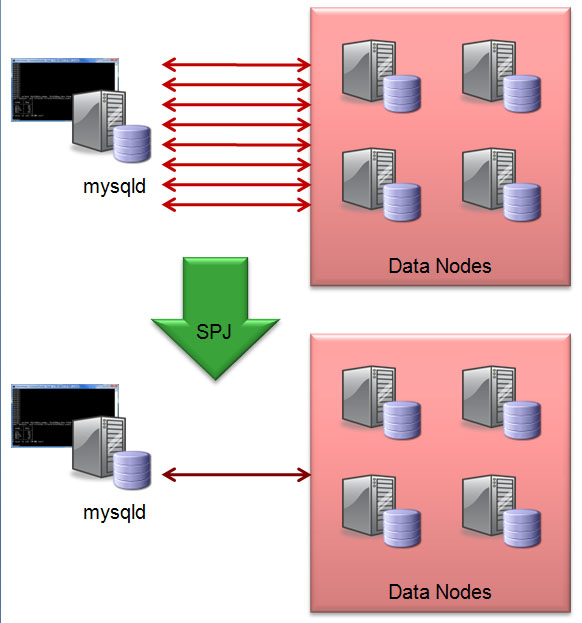
MySQL Cluster Push-Down Joins
A great chance to find out about the “SPJ” project that’s under way to improve the performance of complex table JOINs. A free webinar has been scheduled for Thursday, November 04 at 09:00 Pacific time (16:00 UK; 17:00 Central European Time) – just register for the webinar at mysql.com. Even if you can’t attend, by registering you’ll get an email telling you where to watch the replay shortly after the webinar.
MySQL Cluster performance has always been extremely high and scalable when the work load is primarily primary key reads and write but complex JOINS (many tables in the JOIN and/or a large number of results from the first part of the query) have traditionally been much slower than when using …
[Read more]